Un moteur de recherche de similitudes de joueurs de football de premier plan soutenu par l’IA
L’équipe de Comparisonator est fière et heureuse de vous présenter son tout nouveau moteur de recherche de similarités entre joueurs de football, développé par ses ingénieurs en IA, résultat raffiné d’un an d’efforts de recherche et développement.
Trouver les “jumeaux” dans le style de jeu et le profil d’un footballeur dans le monde entier.
Les recruteurs préfèrent toujours penser en termes de “similitude” lorsqu’ils recherchent des talents, qu’il s’agisse d’un jeune espoir dans les équipes de jeunes ou d’un candidat au transfert de classe mondiale dans les ligues de premier rang. Toutefois, cette tâche est plus difficile qu’il n’y paraît, car la notion de “similarité” est très subjective. En dehors de l’analyse sportive, en raison de ce manque d’universalité, les mesures de similarité constituent l’un des sous-domaines les plus complexes de toutes les applications mathématiques.

Un algorithme révolutionnaire
L’équipe Comparisonator a mis un accent particulier sur la recherche de joueurs ayant des styles de jeu similaires à l’aide d’indicateurs numériques sur le terrain. Nous étions conscients de l’importance de la demande grâce à nos discussions a priori avec de nombreux recruteurs en chef dans le monde entier. C’est pourquoi notre groupe de travail sur l’IA a été mobilisé pour développer un produit satisfaisant il y a environ un an. Nous avons choisi d’utiliser toutes les techniques de pointe en matière d’apprentissage profond et de science des données, ce qui a donné lieu à une architecture prometteuse et innovante, à la fois pour nos clients et pour la recherche universitaire dans le domaine de l’IA.
Les scouts et les professionnels de l’industrie du football font toujours partie intégrante du développement de chaque produit Comparisonator grâce à leurs précieux commentaires, ce qui a également été le cas pour notre algorithme de similarité de l’IA. Grâce à ce cycle de production agile, les paramètres de notre algorithme sont affinés jusqu’à la perfection.
Plus compliqué qu’évident : Style de jeu
Au cœur de notre algorithme se trouve l’objectif de pouvoir caractériser quelque chose d’intrinsèquement complexe et subjectif : le style de jeu. Il semble que ce soit une tâche simple et rapide pour les agents de football professionnels ou les spectateurs ordinaires de faire le lien entre les styles de jeu des joueurs : “… Cet arrière droit me rappelle Bissaka de Manchester United…” Malheureusement, c’est un défi ambitieux pour les informaticiens. Cet arrière droit me rappelle Bissaka de Manchester United…’ Malheureusement, c’est un défi ambitieux pour les informaticiens de pouvoir développer une telle chose en utilisant les grandes données statistiques des footballeurs. C’est pourquoi nous avons développé l’algorithme de l’indice de similarité Comparisonator en utilisant un moteur d’apprentissage profond de pointe comme noyau principal. Comme indiqué précédemment, le style de jeu est un concept subjectif. Il peut varier considérablement d’un recruteur à l’autre. Nos approches complexes d’apprentissage profond permettent de minimiser ce biais, tout en essayant de révéler des modèles cachés peu évidents dans le style de jeu.
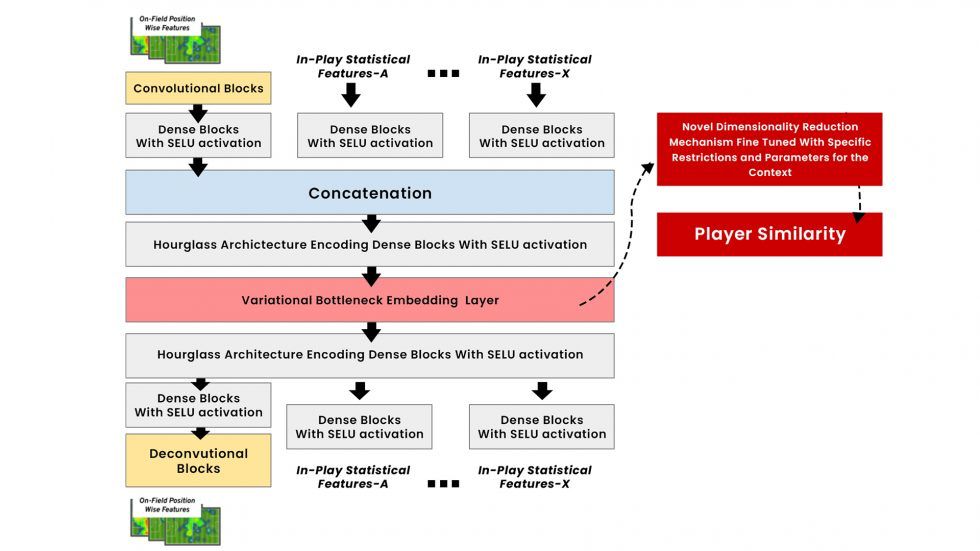
Notre architecture d’apprentissage profond
Dans ce paragraphe, nous présenterons brièvement notre approche, les types de données utilisés, la structure de notre autoencodeur d’apprentissage profond et la méthode de quantification de la similarité des footballeurs. Pour des raisons de secret commercial, nous ne précisons pas explicitement les noms des caractéristiques statistiques et les paramètres de l’architecture d’apprentissage profond utilisée.
Tout d’abord, nous attendons d’un joueur qu’il ait joué au moins 720 minutes sur le terrain pendant la période prévue (saison ou demi-saison), afin de pouvoir disposer de données statistiques suffisantes et significatives.
L’épine dorsale de notre algorithme est un autoencodeur variationnel profond de bout en bout, qui comprend également des blocs convolutifs/déconvolutifs pour coder les données spatiales. L’architecture a été conçue de manière rigoureuse, en choisissant spécifiquement la largeur et la profondeur des couches, les fonctions d’activation les plus appropriées, le régime d’entraînement et le réglage des hyperparamètres.
Outre la nouveauté de l’architecture, des efforts considérables ont été consacrés au choix et à l’ingénierie des caractéristiques. Nous avons déterminé le meilleur ensemble de caractéristiques spatiales et non spatiales, ainsi que leur organisation et leur prétraitement appropriés dans le modèle.
L’innovation réside également dans l’étape finale de notre algorithme : l’extraction statistique des encastrements à partir de la couche variationnelle et la réduction efficace de la dimensionnalité avec une méthodologie appropriée de ces valeurs de contexte sémantique global. Enfin, les similitudes entre les joueurs sont mesurées sur la base de cet ensemble final d’informations réduites.
L’algorithme utilise les dernières techniques d’intelligence artificielle pour mettre en correspondance les footballeurs ayant des profils similaires dans le style de jeu, plutôt que de prendre directement leurs simples métriques de performance, la compétitivité en ligue, l’âge, l’évaluation, etc. Ainsi, plutôt que d’associer les meilleurs joueurs à leurs pairs de classe mondiale ou d’utiliser de simples statistiques clés telles que les buts, les xG ou les passes décisives, notre algorithme d’apprentissage profond apprend un profil global très complexe pour un footballeur dans le jeu. Cela permet aux recruteurs de formuler des requêtes intéressantes, par exemple sur un joueur jeune et abordable, évoluant dans des ligues de niveau inférieur, qui présente un profil de jeu global similaire à celui de Messi. Au cas où une équipe perdrait un joueur particulier en raison d’un transfert, d’une blessure ou d’une baisse de performance, les recruteurs peuvent générer une liste de candidats dont le style correspond à celui du joueur qu’ils doivent remplacer.
Aperçu de notre architecture d’apprentissage profond et de notre technique de mesure de la similarité